RECKONING: Reasoning through Dynamic Knowledge Encoding
Long-context reasoning requires accurately identifying relevant information in extensive, noisy input contexts. In this work, we propose PERK (Parameter Efficient Reasoning over Knowledge), a scalable approach for learning to encode long input contexts using gradient updates to a lightweight model adapter at test time. Specifically, PERK employs two nested optimization loops in a meta-training phase. The inner loop rapidly encodes contexts into a low-rank adapter (LoRA) that serves as a parameter-efficient memory module for the base model. Concurrently, the outer loop learns to use the updated adapter to accurately recall and reason over relevant information from the encoded long context.
Our evaluations on several long-context reasoning tasks show that PERK significantly outperforms the standard long-context finetuning, achieving average absolute performance gains of up to 20% for Qwen-2.5 (0.5B & 7B) on synthetic and real-world long-context reasoning. PERK also maintains its advantages across model scales and families. Compared to specialized long-context LLMs, PERK matches or surpasses their performance. Finally, our analyses show PERK is more robust to reasoning complexity, length extrapolation, and the positions of relevant information in contexts.
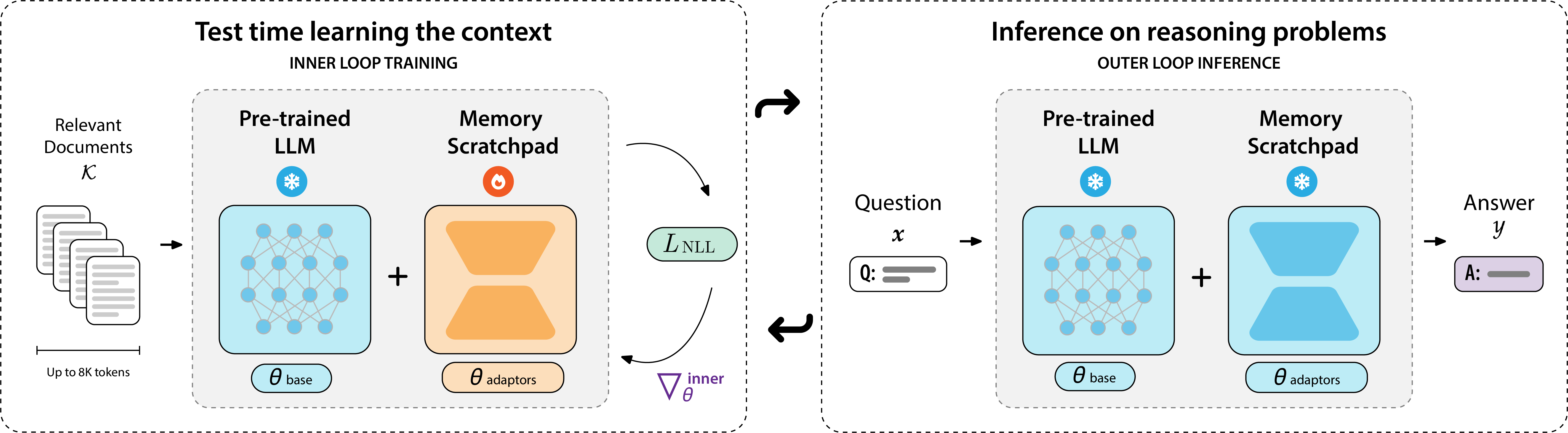
To scale the training of larger and more capable test-time learning models, we propose PERK, which uses a parameter-efficient test-time adaptation to reduce both the size and amount of gradient unrolling required during optimization. Specifically, in the inner and outer loops, we only optimize a parameter-efficient adapter, LoRA, to encode the contexts, and we apply truncated gradient unrolling to reduce the memory cost of backpropagating through the inner loop.
We set the test time learning objective (thus also the inner loop objective) to Causal Language Modeling (CLM) of the context, and set the adaptation algorithm $Alg$ to only update the LoRA parameters. The adaptation algorithm computes the gradients on a batch of sub-sequences from the full context sequence. This compression as a parallel batch(or multiple batches) allows us to process lengthy sequences beyond the model's context window.
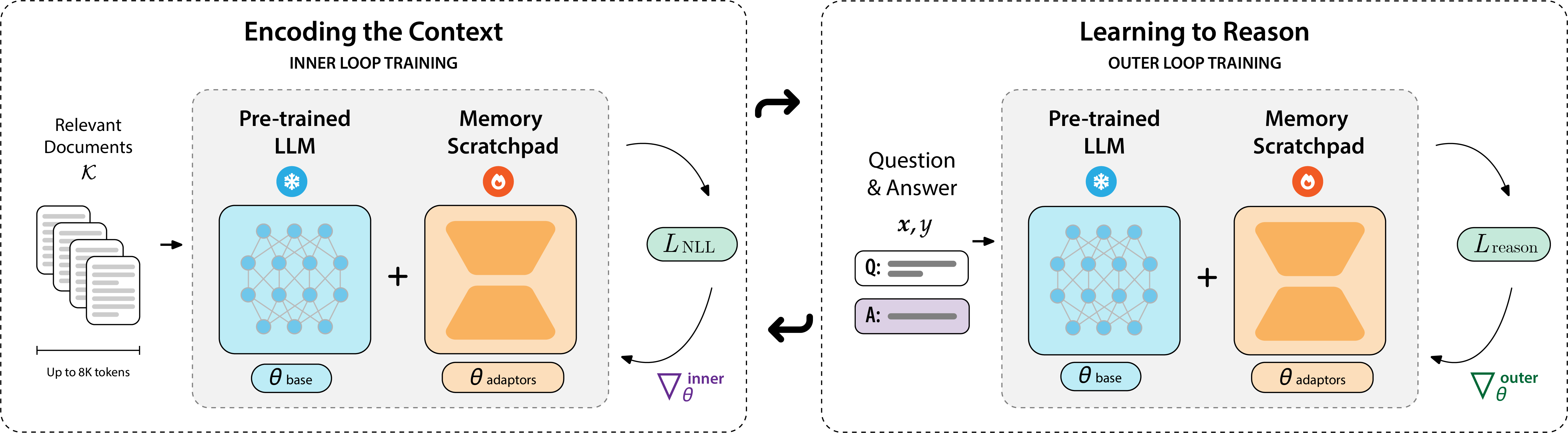
In the outer loop, we optimize the meta parameters of the LoRA module to learn from the corresponding distribution of reasoning problems. The optimal meta parameters minimize the expected reasoning loss of the adapter's adaptation to each reasoning problem, where the adaptation here is the parameter-efficient CLM adaptation of the LoRA meta parameters to the context. The outer loop then trains the model to answer questions using only the information stored in the updated adapter without access to the original text. This meta-learning approach teaches the model not just what to remember, but how to remember effectively.
To make this computationally tractable, PERK employs truncated gradient unrolling. Rather than backpropagating through every step of the inner loop optimization (which would be prohibitively expensive), PERK only retains the computation graph for the final few adaptation steps. In particular, we run the inner loop optimization for all $N$ specified update steps, but only store the computational graph for the last $T \leq N$ steps. This approximation reduces memory requirements dramatically while maintaining performance.
PERK demonstrates strong performance on long-context reasoning tasks, significantly outperforming standard supervised finetuned models with in-context reasoning (FT-ICR). We evaluate PERK in three challenging scenarios: (1) Needles-in-a-Haystack — Reasoning with BabiLong, (2) Drops-in-an-Ocean (DIO), a novel evaluation setting we propose, and (3) Multi-Doc QA with HotpotQA and TriviaQA for real-world long-context reasoning.
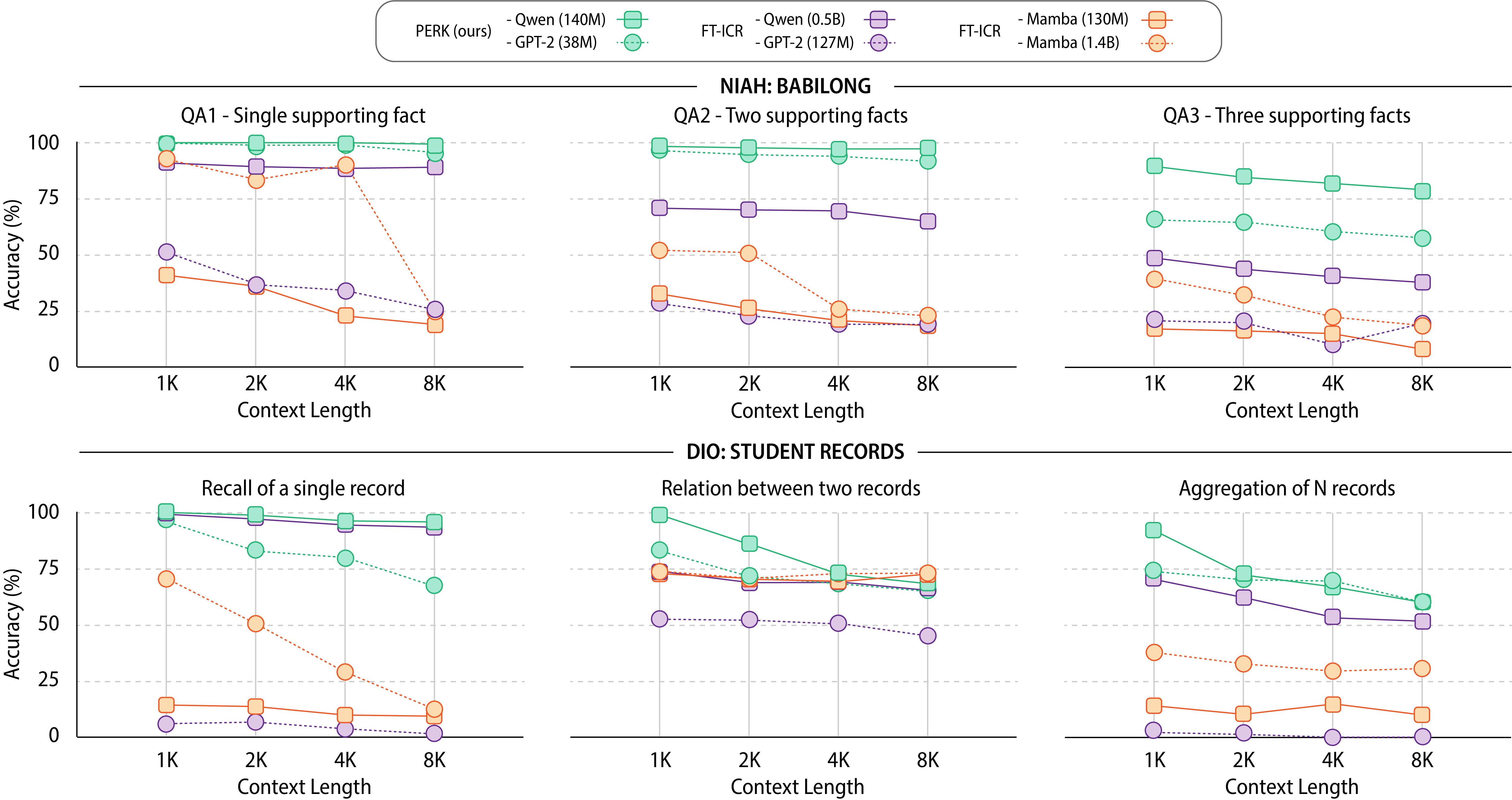
We evaluate PERK on BabiLong, which hides critical facts ("needles") within thousands of tokens of irrelevant text ("haystack"), then requires finding and reasoning over those facts. We test three difficulty levels: single-hop (QA1), two-hop (QA2), and three-hop (QA3) reasoning.
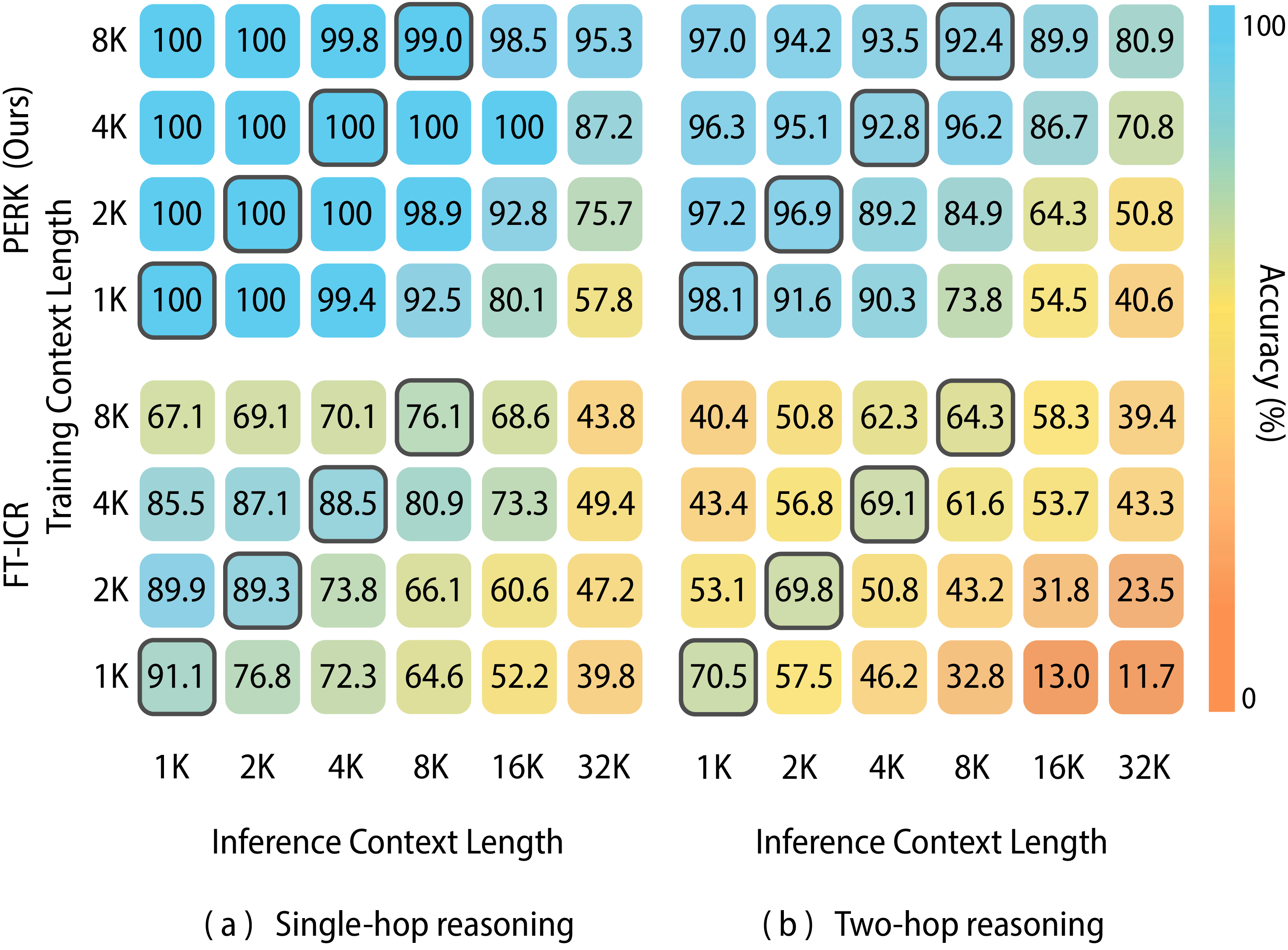
PERK outperforms all baselines across all reasoning depths, including much larger models and specialized long-context models supporting 512K–1M tokens. PERK (Qwen-7B) achieves higher accuracy than FT-ICR (Qwen-7B) at 8K contexts, and when extrapolating to 32K contexts, PERK outperforms FT-ICR by 23 percentage points on average.
On HotpotQA and TriviaQA, which require retrieving and reasoning across multiple documents, PERK (trained on 8K tokens) beats FT-ICR by 15–20% depending on model size. When generalizing to 32K-token contexts unseen during training, PERK maintains a 14–30% advantage.
Compared to specialized long-context models like Qwen-1M and ProLong-512K, PERK matches their performance with far less specialized training. While GPT-4.1 and Gemini-1.5-pro still lead, PERK significantly closes the gap.
Standard NIAH datasets have a fundamental limitation: target information often differs stylistically from surrounding text, making retrieval artificially easy. We propose Drops-in-the-Ocean (DIO), which forms long contexts from structurally similar documents. Our synthetic Student Records dataset simulates a database with evaluation tasks of increasing complexity: (1) Recall (retrieve attributes for a student ID), (2) Relation (compare attributes between two IDs), and (3) Aggregate (max, min, and average grades).
PERK outperforms FT-ICR across all task difficulties and context lengths, with a smaller performance drop at 32K tokens. The performance gap widens monotonically with task difficulty, suggesting PERK enhances complex reasoning rather than merely improving retrieval. Both PERK variants outperform specialized long-context models, and PERK (Qwen-7B) matches or exceeds commercial models even on Aggregate tasks.
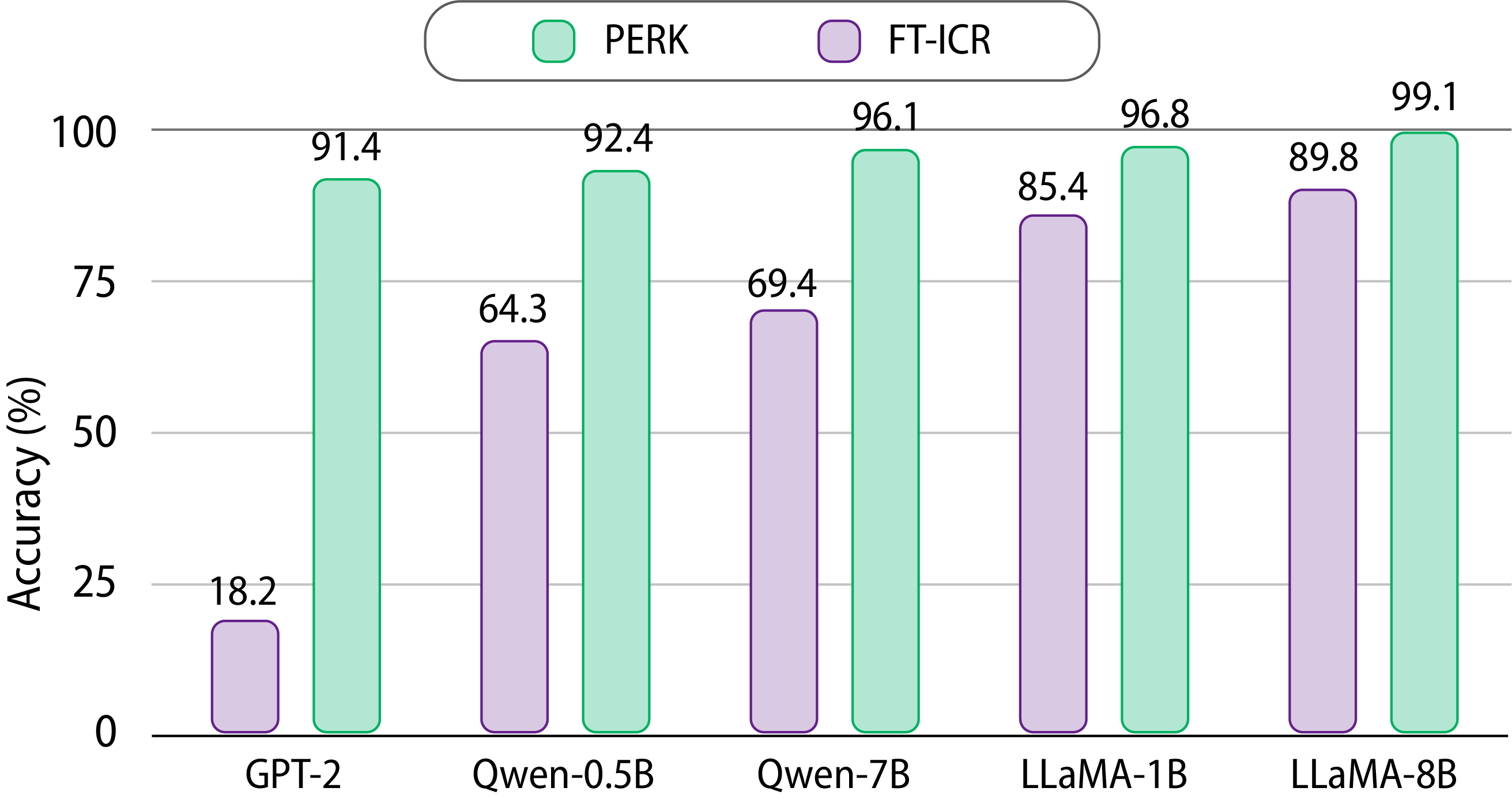
PERK achieves strong performance across GPT-2, Qwen-2.5 (0.5B & 7B), LLaMA-3.1-8B, and LLaMA-3.2-1B families and scales, demonstrating that its advantages represent a fundamentally effective approach for long-context reasoning rather than architecture-specific or scale-specific gains.
We evaluate PERK's robustness to inputs of different lengths than those seen in training. We test for both shorter and longer test-time lengths than the training length. We evaluate using the BabiLong tasks and train a Qwen-2.5-0.5B model using PERK on fixed-length contexts ranging from 1K to 8K tokens. We evaluate each model on contexts ranging from 1K to 32K tokens, measuring each approach's ability to generalize to unseen lengths.
| Model | (a) Single-hop reasoning | (b) Two-hop reasoning | ||||
|---|---|---|---|---|---|---|
| 32K | 64K | 128K | 32K | 64K | 128K | |
| Commercial Frontier Models | ||||||
| GPT-4.1 | 87.8 | 78.7 | 69.4 | 80.6 | 66.4 | 48.2 |
| Gemini-1.5-pro | 87.7 | 82.3 | 73.1 | 56.4 | 48.8 | 40.2 |
| Trained on contexts with >256K tokens | ||||||
| Qwen2.5-7B-Instruct-1M | 65.7 | 30.3 | 21.4 | 35.3 | 21.0 | 12.2 |
| ProLong-8B-Instruct-512K | 41.0 | 33.2 | 24.3 | 29.0 | 18.5 | 17.7 |
| Trained on contexts with 8K tokens (Length Extrapolation) | ||||||
| FT-ICR (Qwen2.5-0.5B) | 43.8 | 34.5 | 0.0 | 39.4 | 11.7 | 0.0 |
| + Yarn + DCA | 59.2 | 35.5 | 25.4 | 42.5 | 26.3 | 18.5 |
| PERK (Ours) | 95.3 | 88.9 | 61.4 | 80.9 | 62.5 | 44.4 |
To stress-test the limit of PERK's length extrapolation ability,
we further test on sequences with context lengths beyond the context window of the Qwen-2.5 model -- 32K tokens.
Specifically, we test on sequences with 64K and 128K tokens.
We show that PERK consistently achieves
stronger length-extrapolation performance than the supervisely finetuned model.
Although with 128K tokens, PERK's accuracy experiences a noticeable drop to 61.4% for QA1 and 44.4% for QA2,
these scores are still substantially better than the 0% absolute performance of the supervisely finetuned model.
When we apply the SOTA length generalization methods, Yarn and DCA, to FT-ICR Qwen,
the baselines show improved generalization on the extreme contexts.
However, Yarn + DCA's extrapolation performance is still far below PERK for both QA1 and QA2 (around 35% lower on average).
Compared to the specialized frontier models, PERK outperforms Gemini-1.5-pro and the two open-source models, and achieves a narrow performance gap to GPT-4.1 on both 64K and 128K contexts. We note, as well, that PERK is only trained on contexts with 8K tokens, while the Qwen-1M and ProLong-512K models have been trained on much longer contexts (> 256K tokens).
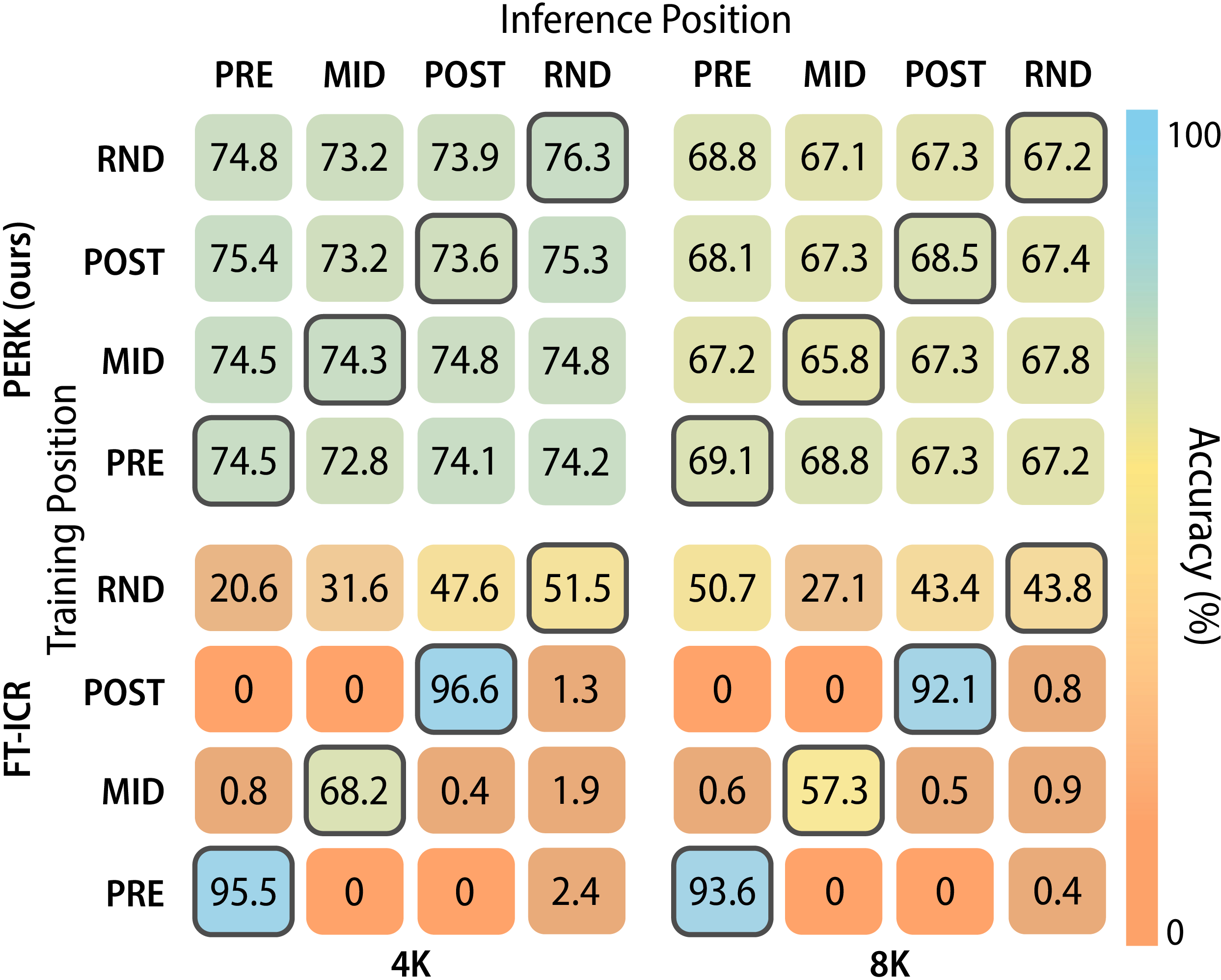
Prior work has shown that the position of relevant information in long contexts affects a language model's ability to utilize that information. We test PERK's robustness to positional biases by evaluating its test-time performance on contexts where the position of relevant information is distributed differently from those seen in training.
When trained on contexts with relevant documents randomly located (Rnd) throughout the context, PERK outperforms FT-ICR. FT-ICR shows large performance drops when the relevant document appears at different locations (Pre, Mid, and Post) at test time. Meanwhile, shifting relevant positions at test-time shows minimal effect (within 1-2%) on PERK.
To further stress-test positional generalization, we also force relevant documents into particular positions during training and testing with positions across the full context. We find that FT-ICR easily overfits to the position pattern, completely failing to generalize to test-time position changes (performance drops to close to 0% when the position shifts at test time).
We evaluate PERK's training efficiency on long contexts by measuring its inference memory cost and run-time, compared to in-context reasoning with supervisely finetuned models.
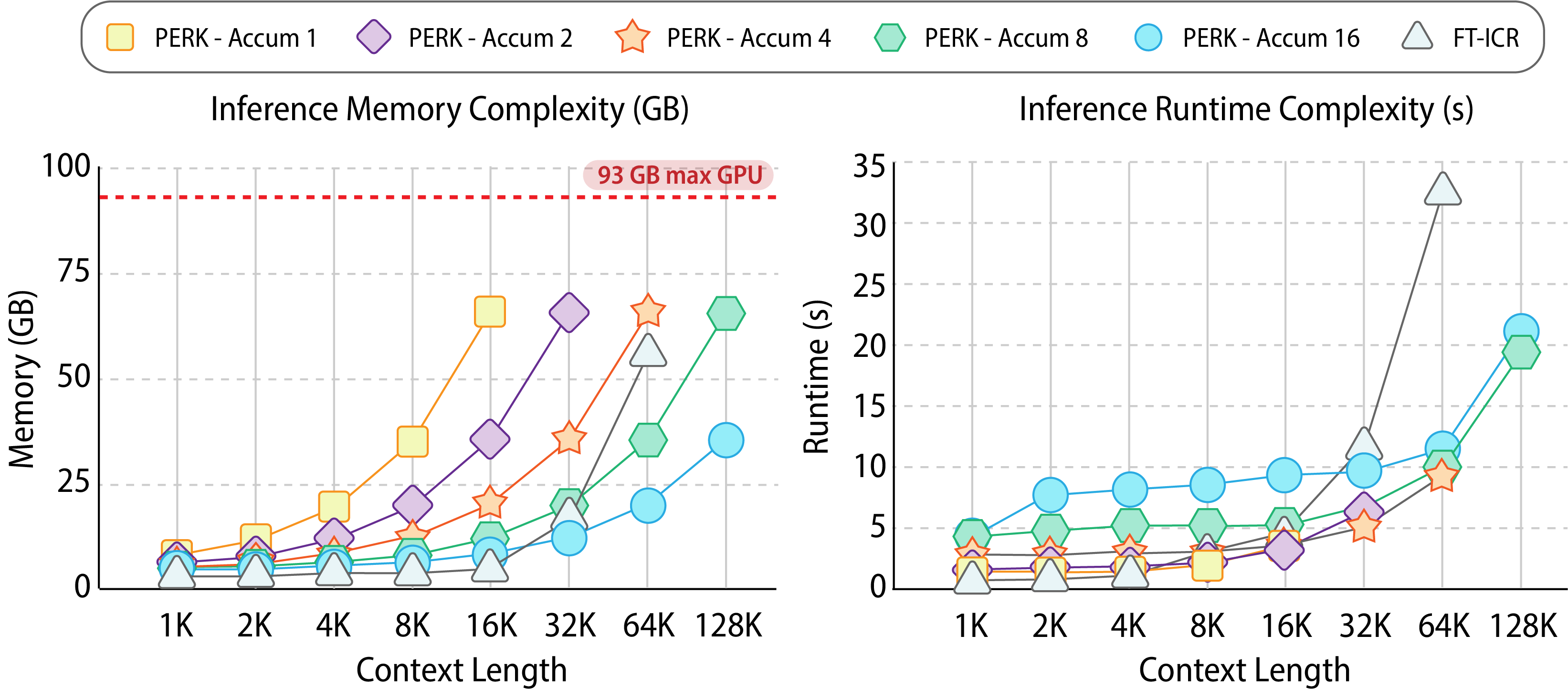
PERK provides more efficient memory and runtime scaling for extremely long contexts compared to FT-ICR. While FT-ICR is initially more efficient, its memory and runtime grow rapidly, leading to OOM errors at a context length of 128K. In contrast, PERK can manage the long sequences through gradient accumulation, which, while increasing runtime, reduces the memory footprint. Ultimately, at 128K tokens, where FT-ICR fails, PERK with 16 steps successfully processes the context using 35.2GB in 20.9s, showing that PERK provides a practical path to handle extreme context lengths efficiently in both memory and runtime when compared to standard approaches.
PERK represents a paradigm shift in how we think about long-context capabilities. Rather than building ever-larger context windows through extensive pre-training, PERK demonstrates that models can learn to internalize context on-the-fly through parameter adaptation. This approach offers several compelling advantages: better generalization to unseen lengths, robustness to information position, and efficient scaling to extreme context lengths.
The method works across model scales (from 0.5B to 8B parameters) and model families (GPT-2, Qwen, LLaMA), suggesting that the core principles are broadly applicable. For practitioners working with long documents—legal contracts, scientific papers, codebases, or multi-document analysis, PERK offers a promising path toward more reliable and capable long-context reasoning.
As language models continue to be deployed in scenarios requiring deep understanding of extensive information, approaches like PERK that fundamentally rethink the context problem may prove essential. The ability to truly learn from and reason over long contexts, rather than simply attending to them, opens new possibilities for what these models can accomplish.
@article{chen2025perklongcontextreasoningparameterefficient,
title={PERK: Long-Context Reasoning as Parameter-Efficient Test-Time Learning},
author={Zeming Chen and Angelika Romanou and Gail Weiss and Antoine Bosselut},
year={2025},
eprint={2507.06415},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.06415},
}